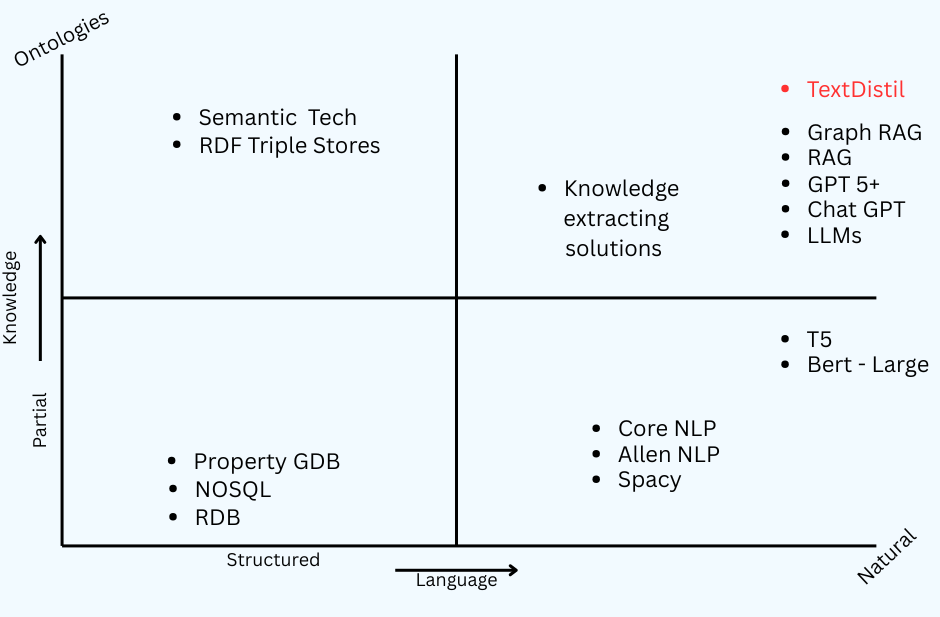
TextDistil targets the cognitive corner of the technology land scape. It is well positioned to deliver novel functionality by leveraging the amazing power of Large Language Models combined with the robust methods of Semantic Technology.
Leverage the power of LLMs and Semantic Technology
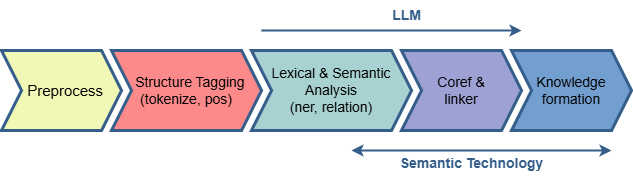
We leverage the awesome power of Large Language Models to tease out the understanding to construct high fidelity domain specific knowledge as described by an Ontology using Semantic Technology.
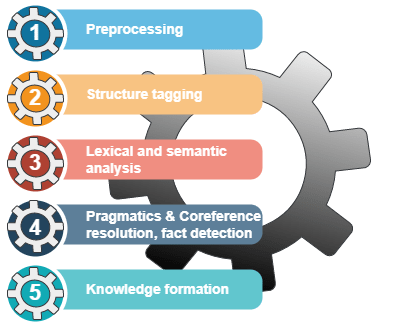
Architecture of TextDistil pipeline lends it self to be domain independent. The pipeline enables ‘no code’ Knowledge Graph generation from Text and adapts to different domains and down stream applications by configuring custom Ontology and custom Taxonomy trained models.