We are delighted to share that Lead Semantics is acknowledged as a top Enterprise AI solution vendor
We are delighted to share that Lead Semantics is acknowledged as a top Enterprise AI solution vendor
Menu
Rise of the NEW AI Stack (GraphRAG - LLM, RAG, Knowledge Graph)
LLM Hallucinations, Lack of Domain Specificity:LLMs (Generative AI) understand natural language questions or requests as input and produce answers in natural language. However, LLMs are prone to producing incorrect answers due to ‘hallucinations’. And, LLMs suffer from the lack of focused domain specificity in the answers they generate.
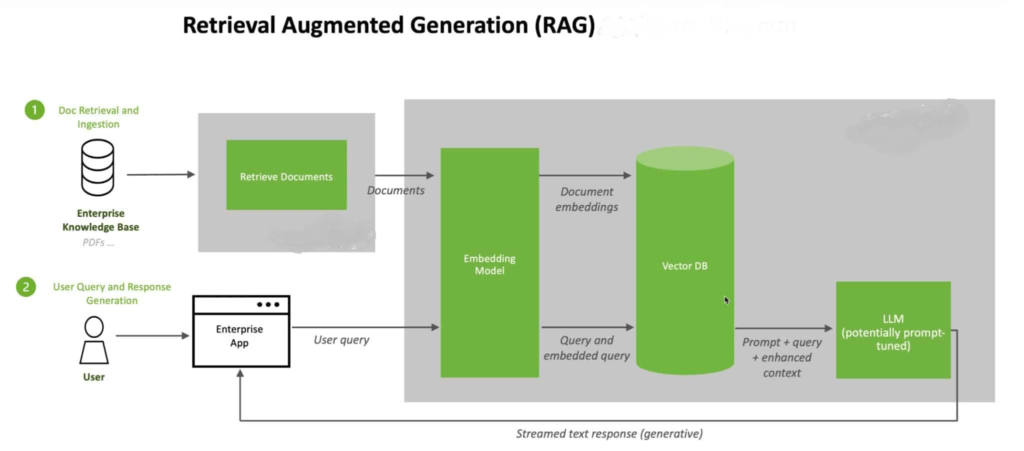
A new technique ‘Retrieval Augmented Generation’ or RAG on top of LLMs has been the go to solution to solve the issues and get improved answers from LLMs.
Semantic Matching & Contextualization: RAG utilizes a database of the embedding vectors of the text within documents from the domain of interest. The user query is transformed into an ‘embedding vector’ and semantically matched against the Vector DB of document vectors. Text corresponding to the matched vectors is collated into the context of the LLM prompt along with the user query. The LLM, now restricted to the context within which to find answers to the user query, is reined in to produce relevant answers.
RAG with LLM technique reduces hallucinations and produces better domain specificity in the answers. RAG is now the popular, practical, and de facto technique for developers and for AI vendors to use in their solutions.
While effective for many use cases, RAG has critical weaknesses, which include inability to leverage the connections that exist among the entities in the text and its inability to handle summaries well. Relations among real world entities that are reflected in the text, are critical to understanding the text. This lack of handling relations points to a critical gap that needs to be fixed.
Enter Knowledge Graphs
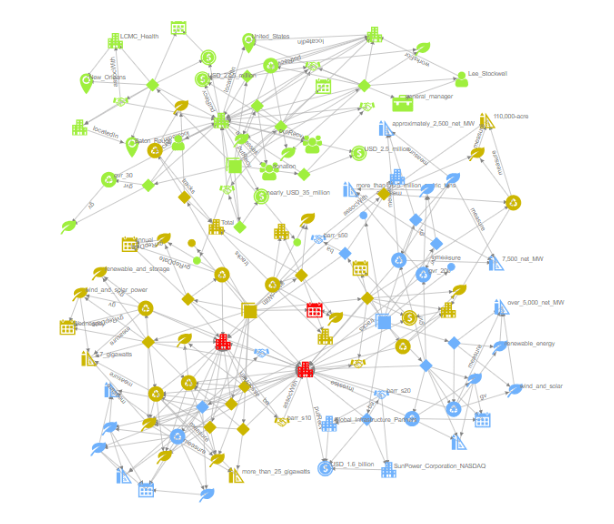
The connections between different entities extracted from the text form the knowledge with a structure of a graph or the knowledge graph.
A new AI stack that incorporates Knowledge graph of entities and their connections on top, fixes the critical gaps in RAG + LLM solutions. Our AI language understanding software, TextDistil, is built on this new AI stack that we are advocating.
Microsoft Research recently alluded to this new technique of overlaying Knowledge Graphs on RAG solutions in their recent article. The new technique is touted as GraphRAG.
TextDistil, GraphRAG on steroids: At Lead Semantics, we developed a ‘Knowledge Graph extraction from Text’ product, TextDistil back in 2020 (discussed in paper). TextDistil was upgraded to LLM+RAG over the course of last year and stands as one of the first production solutions that is built natively using GraphRAG. TextDistil extracts the Knowledge Graph from the RAG store on the fly and populates an RDF triple store. TextDistil answers user questions in natural language against a corpus of documents with accurate and precise answers compared to plain RAG + LLM solution.