We are delighted to share that Lead Semantics is acknowledged as a top Enterprise AI solution vendor
We are delighted to share that Lead Semantics is acknowledged as a top Enterprise AI solution vendor
Menu
Retrieval Augmented Generation
LLMs Fall Short in Structured Data Analysis:Large Language Models (LLMs) are the pre-trained, general purpose foundational models. LLMs, a form of Generative AI come with the risks of hallucinations, biases, incorrect responses while lacking explainability of the results they produce. Further, without being fine-tuned to specific domains LLMs remain inadequate to service applications targeting specific domains. All these reasons have confirmed to the enthusiasts and early adopters that LLMs alone are not enough for structured and consistent data analysis in the enterprise.
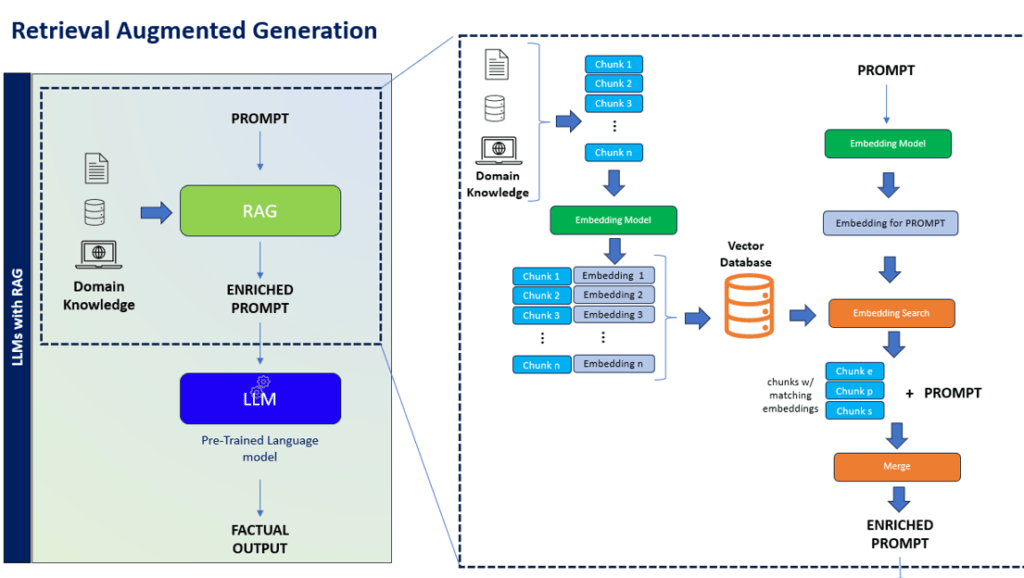
Integrating Retrieval and Generative AI for Enhanced Search: A newer technique Retrieval-augmented generation (RAG) solves the two critical problems of ‘subject specificity’ and ‘hallucinations’ (to a practical and useful extent) and boosts the overall performance of LLM searches. RAG approach forces an LLM to only use the supplied ‘subject specific knowledge base’ such as a specific document corpus when generating answers. With RAG, LLM is not generating its answers by just using what the LLM is trained on during pre-training. The RAG approach uses a smaller knowledge base that is of a (likely) single subject area compared to the immense pretraining data pertaining to every subject area known to humans as in the case of LLMs, which leads to addressing the two critical problems mentioned before. It is well known now that RAG improves the quality of the generated responses by the LLM in the enterprise.
Optimizing Search and Analysis with RAG Architecture: The relative ease of implementing a RAG solution for document and content analysis lies in its architecture. The client data is preprocessed through an embedding model that converts data into a series of vectors and indexed in a vector database. During the search time, the natural language query string is vectorized by the same embedding model and the resulting query vector is used to lookup matching vectors from the client data vector database. These answer vectors point to corresponding blocks of text in documents of the source corpus. The blocks of text are collated to form the new context for the LLM to get an answer for the original user query. The response to the query in the form of summary answers are human-like and come with citations of the underlying documents and blocks of text that contribute to the answers.
Role of RAG in the knowledge workflows of the modern enterprise: Typical modern day white collar work involves handling and interpreting information gleaned off various text sources – emails, articles, bulletins, documents, etc. LLMs with RAG offer practical assistance to people in such work. Baseline RAG however has few drawbacks such as struggling to connect the dots consistently and to fully grasp concepts over a large set of documents. A recent technique GraphRAG on the other hand uses LLM-generated knowledge graphs to not only provide accurate answers but also provide instant verifiability with links to the underlying supporting text. GraphRAG drastically improves the quality of search results by correcting the shortcomings of RAG. Yet, RAG solutions even as they leave out certain problems unaddressed, they have a definite place in the search and analysis solution space in an enterprise, given that the solution is uncomplicated. RAG solutions can be implemented and the advantages felt in a shorter period of time, at a cheaper cost.
TextDistil Revolutionizes Search and Content Analysis:TextDistil is a natively GraphRAG solution and it also implements the RAG solution. Having both RAG and GraphRAG solutions available within, TextDistil covers the entire gamut of use cases that arise in ‘enterprise search and analysis’. These use cases range from answering questions instantly against loaded corpus of documents to use cases that expect most accurate answers and to high value use cases that require automatic creation of a knowledge graph of facts extracted from the corpus that can be integrated with the Enterprise Knowledge Graph for on-going Business Intelligence and Analytics.
Conclusion: Retrieval-augmented generation (RAG) helps overcome critical limitations of LLMs targeting many use cases in the enterprise. GraphRAG takes this further, making answers more accurate and trustworthy leading to most effective document analysis. TextDistil our language comprehension solution implements both RAG and GraphRAG within the same tool, thereby making it an effective solution in the enterprise. Send us an email or contact us to checkout TextDistil for your document search and analysis needs.