
Text To Knowledge and Natural Language Q/A system
We used early versions of TextDistil to develop a custom Knowledge extraction from K12 Biology textbook for a renowned US AI research lab. Resulting Knowledge base was made available to students as the ‘tutor’ that answered questions in natural language.
Text Extraction
We automated invoice processing at a major US customer. The customer had hundreds of invoice types in various formats: JPEG, PDF, PNG etc. We delivered the Deep Learning Pipeline that extracted relevant parts of the invoice, like the amounts, dates etc. and populated a database. The output database automated accounts payables.


Sentiment Analysis
Our sentiment analysis solution helped a large auto parts manufacturer understand customer sentiment towards their products. Customer reviews and unsolicited comments were extracted from various web channels: Facebook, Twitter, Instagram, etc. Delivered sentiment analytics on product, price, location, demographics.
Keyword Extraction; Topic Modeling; Document Similarity
One of the largest petroleum companies in the Middle East has millions of documents related to petrochemicals in their repositories. Our solution automated identifying the duplicates, identifying similar documents of different versions using ‘keyword extraction’, ‘topic modeling’ and ‘document classification’.

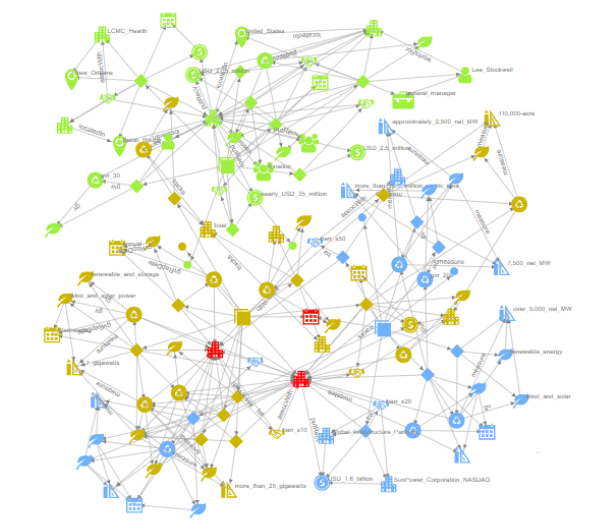
Graph Algorithms and Analytics
We created individual ‘patient graphs’ for patients of a major hospital network in the US. Patients’ data in the hospitals spans health, clinical, genetic, payer, procedure, device, lab test data, etc. Data for this hospital network consisted of data for more than 1 Million patients and multiple terabytes. We encoded the data into RDF and populated a W3C compliant triple store. From the triple store, we generated a graph and algorithmically tagged individual patient subgraphs. Patient graphs were to be used to deliver personalized care by downstream applications, ML Pipelines, etc.
The solution was an AI Pipeline that included 1) Encoding the terabytes of data into RDF using medical taxonomies and vocabularies 2). Graph generation leveraging the structural relationships in the data 3). Running distributed graph algorithms (modified pregel) 4). Identifying and tagging the patient graphs 5). Updating patient graphs in Hospital Knowledge Graph. The AI Pipeline was implemented using TextDistil (structured data), Apache Spark, GraphX, HDFS and RDF Triple Store.